Back to Blog
Finding the Data That Breaks Your Pose Estimation Model

.webp)
Uncovering hidden failure patterns in pose estimation using latent space analysis with Tensorleap.
When pose estimation models fail, the reasons are rarely obvious. Aggregate metrics smooth over structure, and manual inspection of individual samples often leads to intuition-driven guesswork rather than understanding.
This is a recurring challenge in deep learning debugging: knowing not just where a model fails, but what it has learned, and how those learned concepts influence performance and behavior.
Tensorleap addresses this challenge by creating a visual representation of the dataset as seen by the model itself. By analyzing internal activations, Tensorleap reveals how the model interprets data, uncovers the concepts it has learned, and connects those concepts directly to performance patterns.
In this post, we analyze a pose estimation model trained on the COCO dataset, showing how latent space analysis exposes hidden failure patterns that systematically degrade model performance.
Before debugging failures, it helps to start with a more fundamental question: How does the model internally organize the data it learns from?
Tensorleap captures activations across the model’s computational graph and embeds each input sample into a high-dimensional latent space. This space is then projected into an interpretable visual representation, where proximity reflects similarity in how the model processes images.
In effect, this creates a map of the dataset from the model’s point of view- revealing how inputs are grouped based on learned representations rather than labels or predefined rules.
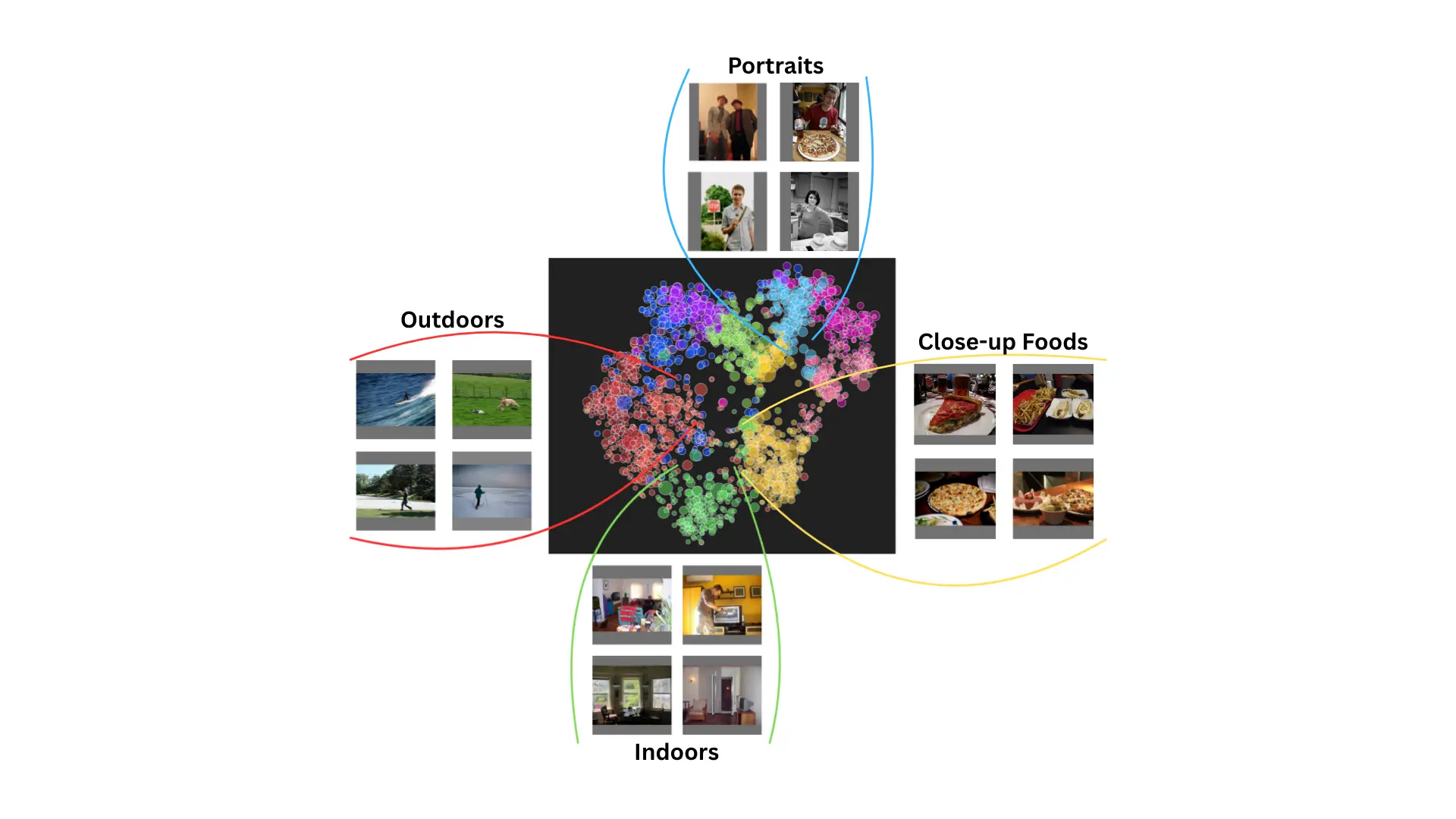
Once the latent space is constructed, samples are automatically clustered based on their learned representations. These clusters reflect concepts learned by the neural network, not categories imposed by the dataset.
Overlaying dataset metadata on this space reveals strong semantic alignment. For example, indoor scenes containing household objects naturally group together, confirming that the latent space encodes meaningful semantic structure.
.webp)
Each latent cluster is linked to performance metrics, loss components, and dataset metadata. Clusters that contribute disproportionately to error are identified as performance aggressors- groups of samples that actively degrade model behavior during training and inference.
Below, we examine two such aggressors uncovered in the pose estimation model.
One cluster exhibits classification loss more than twice the dataset average.
.webp)
This cluster is dominated by close-up images with heavy occlusion, including food on tables and pets such as cats. Most images contain no people, and when humans do appear, they are often partially visible.
Despite this, the model frequently predicts the presence of a person. Loss spikes most sharply in images with zero people, indicating a systematic bias toward positive human detection.
Why this matters:
This cluster does not represent isolated errors. These samples disproportionately influence classification loss and reshape the decision boundary, reinforcing false positives during training.
Isolating this cluster makes it possible to reason about how close-up, non-human imagery biases the classifier and to evaluate whether these samples should be treated differently during analysis or training.
Another cluster shows degradation across all loss components: classification, bounding boxes, pose, and keypoint estimation.
.webp)
These samples correlate strongly with sports and stadium scenes containing both players and spectators. Inspection of annotations reveals that many visible people are partially or entirely unlabeled for pose.
Comparing object-detection and pose annotations shows a median gap of 13 people per image, exposing inconsistency in what constitutes a labeled subject. Activation heatmaps confirm that the model attends to both labeled players and unlabeled spectators, leading to contradictory training signals.
Why this matters:
Performance degradation in these scenes is driven by label inconsistency, not pose complexity. Without distinguishing between the two, errors in crowded environments are easily misattributed to difficult motion or insufficient model capacity.
These failure patterns share three characteristics:
By visualizing how the model interprets the dataset and linking learned concepts to performance, teams gain a grounded understanding of why models fail and where deeper investigation is required.
This approach enables more informed decisions around data inspection, targeted analysis, and follow-up experimentation.
Pose estimation models do not fail randomly- they fail in patterns shaped by data, labels, and learned representations.
By creating a visual representation of how the model sees the data, Tensorleap uncovers hidden failure patterns and reveals the dataset concepts that most strongly affect performance.
When metrics stall and intuition runs out, the answer is often already there- embedded in the model’s latent space.