Back to Blog
Uncovering Hidden Failure Patterns In Object Detection Models

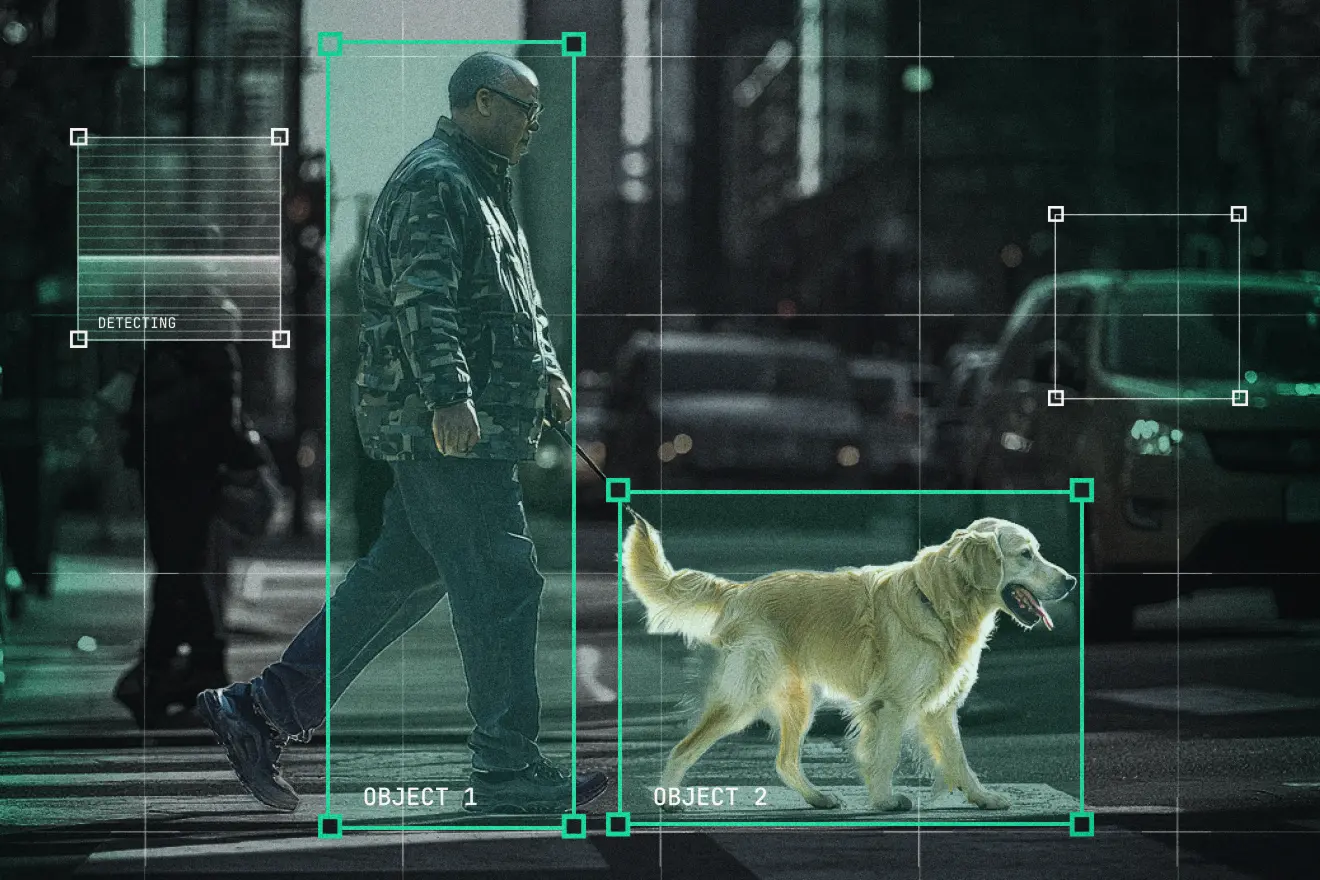
How to diagnose overfitting, scale sensitivity, and labeling inconsistencies beyond aggregate metrics
Modern object detection models often achieve strong aggregate metrics while still failing in systematic, repeatable ways. These failures are rarely obvious from standard evaluation dashboards. Mean Average Precision (mAP), class-wise accuracy, and loss curves can suggest that a model is performing well- while masking where, how, and why it breaks down in practice.
In this post, we analyze a YOLOv11 object detection model trained on the COCO dataset and show how latent space analysis exposes failure patterns that standard evaluation workflows overlook. By examining how the model internally organizes data, we uncover performance issues related to overfitting, scale sensitivity, and inconsistent labeling.
Object detection systems operate across diverse visual conditions: object scale, occlusion, density, and annotation ambiguity. Failures rarely occur uniformly; instead, they cluster around specific data regimes.
However, standard evaluation metrics average performance across the dataset, obscuring correlated error modes such as:
Understanding these behaviors requires analyzing how the model represents samples internally-not just how it scores them.This analysis was conducted using Tensorleap, a model debugging and explainability platform that enables systematic exploration of latent representations, performance patterns, and data-driven failure modes.
Deep neural networks learn internal representations that encode semantic and spatial structure. In object detection models, these latent embeddings determine how different images are perceived as similar or different by the model.
By projecting these embeddings into a lower-dimensional space and clustering them, we can observe how the model organizes the dataset according to its learned features.
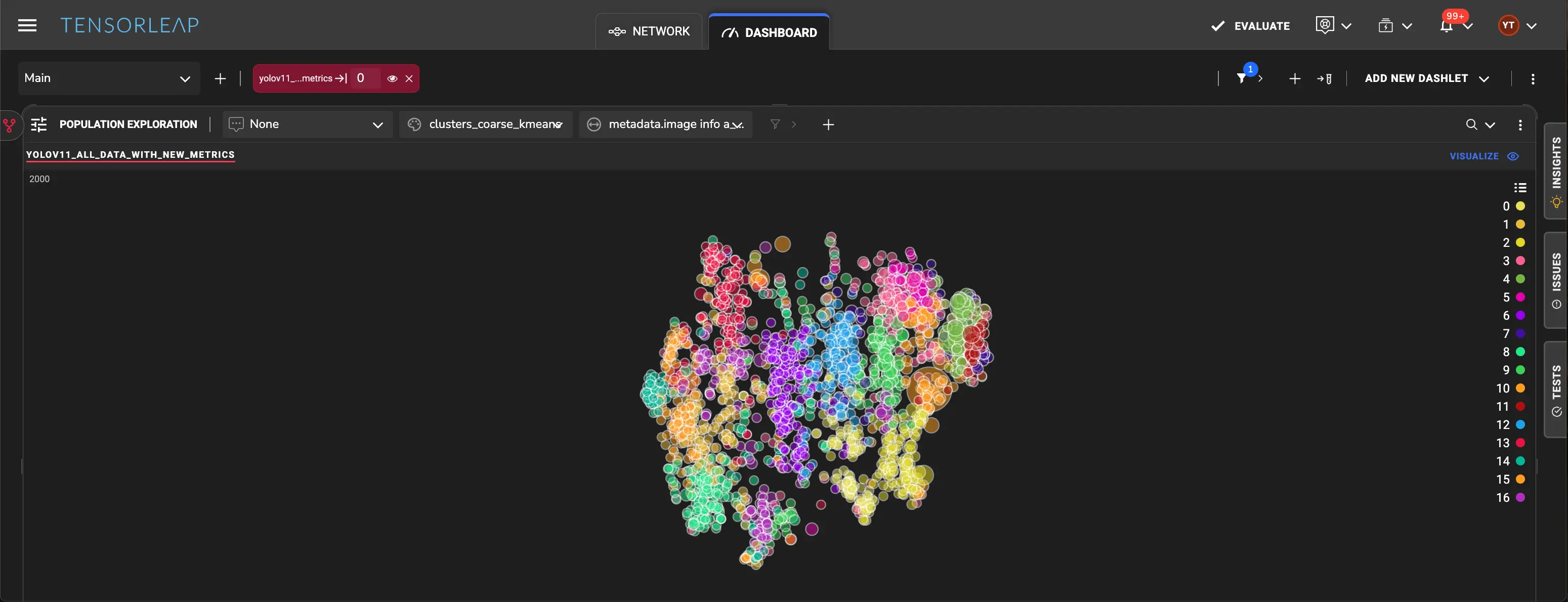
Clusters in this space often correspond to shared performance characteristics. Regions with elevated mean loss or skewed data composition point to systematic failure modes rather than isolated errors.
One prominent cluster is dominated by images containing train objects with minimal occlusion on training samples compared to validation samples. When the latent space is colored by the number of train objects per image, this region becomes immediately apparent.
.webp)
This cluster exhibits low bounding box loss on the training set but significantly higher loss on validation data. The samples are strongly correlated with low occlusion, indicating that they represent visually “easy” cases.
The imbalance suggests that the model has overfit to these simple examples, memorizing their patterns rather than learning features that generalize. When validation samples deviate slightly, such as containing higher object overlap, performance degrades sharply.
A separate low-performance region emerges when the latent space is examined alongside bounding box size statistics. Samples dominated by small objects consistently show higher loss values.
Qualitative inspection of samples from this region confirms the pattern: the model reliably detects large objects while frequently missing smaller ones in the same scene. This behavior is reinforced by a clear trend in the data- loss increases as object size decreases.
Rather than sporadic errors, small-object failures appear as a structured limitation tied to how the model represents scale internally.
Another low-performing cluster is dominated by images containing books. Coloring the latent space by the number of book instances reveals a strong concentration of such samples.
Inspection of these images exposes multiple labeling inconsistencies:
Layer-wise attention analysis further reveals that earlier layers focus on individual books, while final layers often collapse attention onto entire shelves. This mismatch suggests that fine-grained representations exist internally but are not consistently reflected in final predictions.
.webp)
As the number of books per image increases, loss rises accordingly, reinforcing the conclusion that labeling ambiguity directly degrades model performance.
These findings highlight a fundamental limitation of aggregate evaluation metrics: they describe how well a model performs on average, but not where or why it fails.
Latent space analysis exposes:
Crucially, these issues emerge as structured patterns across groups of samples, not as isolated mistakes.
Object detection models can appear robust while harboring systematic weaknesses that only surface under specific conditions. By analyzing latent space structure and correlating it with performance and metadata, we can uncover hidden failure patterns and trace them back to data properties and representation gaps.
This shifts model debugging from reactive error inspection to evidence-based understanding, grounded in how the model actually perceives the dataset.